ChatGPT 外,我用這方法搞定 AI 系列圖片生成!

我想從上週以來,各位讀者的社群都被 ChatGPT 最新的生圖模型洗版了吧,那鋪天蓋地的吉卜力風格圖片,是否也讓你躍躍欲試?但當你興奮地想用它為專案製作一系列主角相同、動作各異的圖片時,是否發現——生成的結果雖然不錯,但是由於服務的爆火,導致生圖的限制越來越多,耗費時間越來越長,讓你耗費大量時間卻得不到滿意的素材?如果你也遇到了這個「系列圖片」生成的瓶頸,那麼這篇文章或許能提供一個 ChatGPT 之外的有效解方。
這個生圖模型為何能紅?又為何讓人卡關?
ChatGPT 更新的這個「自迴歸模型」生圖功能,無疑是近期 AI 界的焦點。相較於先前主流的「擴散模型」(如 Stable Diffusion、Midjourney),它在理解自然語言、直接生成多樣化內容上似乎更勝一籌。理論上,生成系列圖片——比如讓同一個角色擺出不同姿勢——應該是它的強項。很多人也確實用它快速製作了 LINE 貼圖等創意內容,這也是它爆紅的主因。
然而,熱潮的背後是現實的骨感。首先是使用體驗的下滑:生成速度變慢、額度限制變多、有時甚至「降智」般地無法理解指令。更關鍵的是,在我嘗試將它用於遊戲專案的素材製作時,發現了更深層的問題。
我近期需要為一款遊戲化健身 APP 製作一系列由同一位教練演示不同動作的圖片。起初我寄望於 ChatGPT,但實際使用後發現,即使是新模型,在要求嚴格的人物一致性時,表現仍不穩定。有時人物的臉部細節會模糊不清,五官比例偶爾失調,或是整體風格難以完美統一,總讓我覺得「差點意思」,不夠精美。
同時,為了製作一款像素風桌面小遊戲的 Sprite Sheet(連續動畫圖),我也用 ChatGPT 進行了測試。雖然單張效果驚豔,但連續生成三張就常需等待冷卻,有時一張圖甚至要花 2-3 分鐘,這對於需要大量且快速產出素材的開發流程來說,效率實在太低。

ChatGPT 之外的選擇:ImageFX 的驚喜與挑戰
在 ChatGPT 的效率與美感瓶頸下,我轉向了 Google 的 ImageFX(目前仍需申請試用)。我之前文章的一些配圖就依靠它,其生成單張圖片的美感和質感往往更符合我的期待,速度也較快(通常一分鐘內生成四張供選擇)。

但 ImageFX 同樣基於「擴散模型」,這意味著它在生成系列圖片時,「人物一致性」的老問題依然存在。常常是第一張圖令人滿意,但當我試圖讓同一個角色換個動作時,角色的服裝細節、髮型,甚至臉部特徵都可能悄悄「飄移」,一致性難以保證。

Aha Moment 與步驟優化
就在我快要放棄,準備回頭硬啃 Stable Diffusion 或接受 ChatGPT 的不完美時,我意外發現了一個結合 Google 工具鏈的方法,有效地解決了 ImageFX 的一致性問題! 這個發現讓我的素材製作流程豁然開朗。
那麼,我是如何用 ImageFX 製作一系列高度一致的圖片呢?
- 起點:獲取基礎人物
- 在 ImageFX 或 Gemini (Flash 2.0 模型) 中,使用簡單提示詞生成一張你大致滿意的人物圖(例如:「一位穿著運動服的亞洲女性健身教練,笑容燦爛,背景為明亮的健身房」)。
- 關鍵一步:讓 Gemini Pro 優化提示詞
- 將步驟 1 生成的滿意圖片 或 你對理想人物的詳細描述,提供給 Gemini 2.5 Pro (或其他強大的語言模型)。
- 要求它:「請根據這張圖片/我的描述,為 Google 的 Imagen 3 模型 (ImageFX/Flash 2.0 使用的模型) 生成一段詳細的、結構化的英文提示詞,以確保能穩定重現這個人物的樣貌特徵。」
- [為何要這樣做?] Gemini Pro 通常能生成比我們隨手寫的更精確、更符合 AI 模型偏好的提示詞,包含臉部特徵、服裝細節、光線、風格等,這是提高後續一致性的基礎。
- 生成基準圖:
- 將 Gemini Pro 生成的詳細提示詞貼回 ImageFX 或 Flash 2.0,生成圖片。微調提示詞(或讓 Gemini Pro 再次優化),直到獲得一張你非常滿意的「基準人物圖」。
- 生成系列動作 (核心技巧):
- 使用 ImageFX:
- 在生成滿意的基準圖後,找到並「鎖定 (Lock)」該圖片的「種子 (Seed)」。
- [為何鎖定 Seed 有效?] Seed 控制了生成過程中的隨機性。鎖定它,意味著 AI 在生成新圖時會基於與基準圖非常相似的初始噪點,更容易保持人物和風格的一致性。
- 現在,在原提示詞後面加入你想要的動作描述(例如:", doing jumping jacks" 或 ", lifting dumbbells"),重新生成。你會發現人物一致性大大提高!主要需要調整的可能是動作的自然度和準確性。
- 使用 ImageFX:
- 使用 Gemini (Flash 2.0):
- 好消息是: 根據我的測試,Flash 2.0 對話模式下的 Imagen 3 似乎能更好地理解上下文。
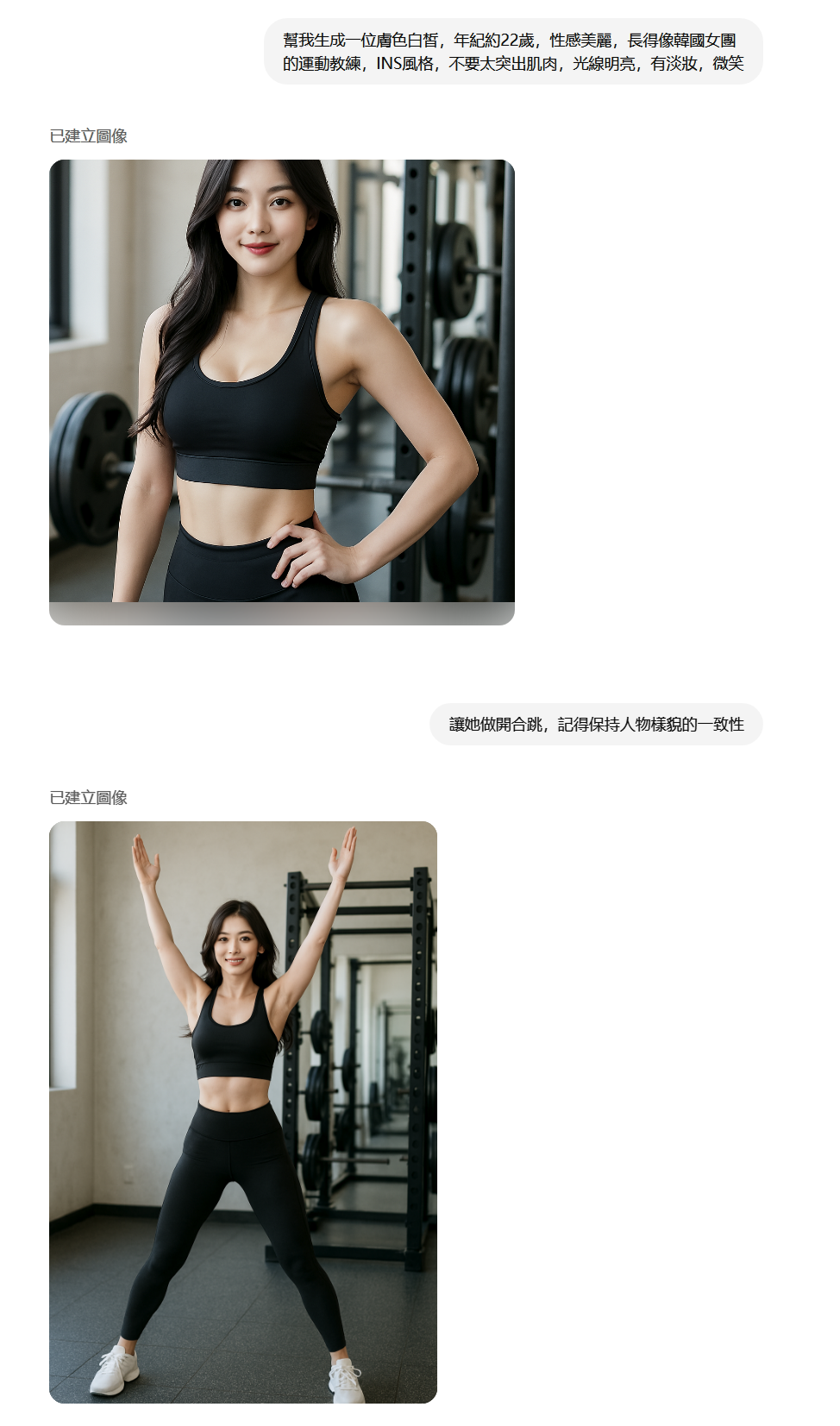
- 在生成滿意的基準圖後,直接在對話中繼續要求:「很好,現在讓她做開合跳 (Now have her do jumping jacks)」。Flash 2.0 通常能較好地保持人物一致性,甚至對動作的理解有時優於 ImageFX。
- [我的經驗]:同樣是「開合跳」這個動作,我在 ImageFX 中反覆調整提示詞並鎖定 Seed,最好也只得到差強人意的結果;但在 Flash 2.0 中直接要求,第二次生成就得到了一張動作合理、人物一致的滿意圖片。
- 迭代優化:
- 如果生成的動作不理想,或一致性仍有偏差,可以嘗試:
- 微調動作描述。
- 回到步驟 2,讓 Gemini Pro 針對特定動作再提供更精確的提示詞片段。
- 在 ImageFX 中嘗試不同的 Seed,有時會有意外收穫。
- 如果生成的動作不理想,或一致性仍有偏差,可以嘗試:

透過這個流程,我終於成功生成了所需的 15 張運動示範圖!不僅人物保持了高度一致(臉部、髮型、服裝基本不變),省去了大量手動修改或反覆生成的挫敗感,而且在真人照片風格上,Imagen 3 的質感和細節表現甚至超出了我最初用 ChatGPT 時的預期!後續我將此流程應用於像素 Sprite Sheet 的生成,同樣取得了非常好的效果。
美女教練測試連結:https://g.co/gemini/share/e0a00eb307ae
2D像素Sprite Sheet測試:https://g.co/gemini/share/1b4b9f5f04ee
正是這樣的探索與突破,促使我寫下這篇文章,當然,我自己在測試的過程中,也懷疑過,Google 應該有為了因應 ChatGPT,偷偷的提升了 Imagen 3 的能力但沒有明說,畢竟在之前也不是沒人做過我這樣的嘗試,但是生成效果都沒有那麼好,5月下旬就是今年的 Google I/O,到時候Google應該會丟出許多重磅AI產品,非常令我期待,畢竟目前最新的 Gemini 2.5 Pro 真的上帶給我最多AI幸福感的模型。
用 AI 做些什麼,真的很有意思!
這次解決圖片生成難題的經驗,也讓我更深刻體會到「用 AI 做些什麼」的樂趣與力量。這和我近期投入「Vibe Coding」(基本上是用自然語言和 AI 一起寫程式)的體驗不謀而合:AI 正在成為強大的槓桿,讓我們這些非技術背景的人也能跨越技能門檻,將創意和想法付諸實踐。
無論是克服圖片一致性的挑戰,還是透過 Vibe Coding 快速搭建 APP 原型,核心都是一種主動運用 AI 來解決問題、創造價值的思維。有了這樣的體驗之後,我真心認為,所有從事企劃、行銷、PM、營運,任何需要將想法落地、需要產出內容或產品原型的人,都值得去探索如何將 AI 融入自己的工作流。
如果你也是一位需要產出視覺素材的行銷人員、內容創作者、產品經理,或是任何卡在「想法很多,執行很難」階段的實踐者,希望我這次的 AI 系列圖片生成經驗分享,能為你帶來一些啟發與實用的幫助。 後續我也會繼續分享我使用 AI(包含 Vibe Coding)開發遊戲化健身 APP 的心得與思考,敬請期待!



